原文:Improving skill-creator: Test, measure, and refine Agent Skills,发布于 2026-03-03,Anthropic 官方博客。
Anthropic 悄悄给 skill-creator 推了一波大更新。这次更新的核心是把软件工程那套测试/基准/迭代的思路搬进 skill 开发流程,而且不需要你会写代码。
我把原文翻译了一遍,加了一些自己的理解。
两种 Skill,问题不一样#
先从一个基础问题出发:一个 Agent Skill 到底是用来干什么的?
Anthropic 把 skill 分成两类:
能力增强型(Capability Uplift) Claude 本身做不到,或者做得不稳定,然后你写一个 skill 来弥补这个缺口。比如官方的那些文档生成 skill——它们把技巧和模式编码进去,让输出质量比单纯 prompt 高一截。
偏好编码型(Encoded Preference) Claude 其实能干每一步,但你的团队有自己的工作流,skill 的作用是把这个流程固化下来。比如按照固定标准审 NDA 合同、按模板写周报这种事。
这个区分很有意思,因为它们失效的方式不一样:
- 能力增强型 skill 会随着模型变强而"过时"——当 Claude 本体已经能通过你写的测试,skill 就没必要存在了
- 偏好编码型 skill 更耐用,但它的价值完全取决于它跟你真实工作流的契合程度
所以两种 skill 都需要测试,但原因不同。
Eval:把"好像能用"变成"确认能用"#
新版 skill-creator 帮你写 eval,说白了就是给 skill 写测试用例。
流程很简单:写几个测试 prompt(可以附文件),描述"什么样的输出算对",然后跑一下,看 skill 有没有达标。
Anthropic 拿他们自己的 PDF skill 举了个例子:之前处理没有可填字段的表单很烂,Claude 要在没有参照的情况下定位文字坐标,基本就是蒙。Eval 把这个问题隔离出来,修复后,定位逻辑锚定到提取出的文字坐标上,问题解决。
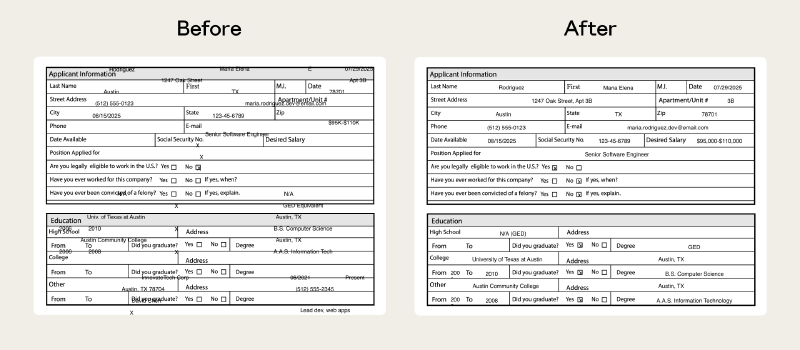
Eval 最重要的两个用途:
① 抓质量回归 模型在升级,基础设施在变,上个月好用的 skill 这个月可能就跑偏了。在新模型上跑一遍 eval,能在问题影响到实际使用之前提前发现。
② 知道什么时候可以删掉 skill 了 这个主要针对能力增强型 skill。如果不加载 skill,基础模型本身就能通过你的 eval,说明 skill 里的那些技巧已经被吸收进模型的默认行为了。skill 没坏,只是不再必要了。
Benchmark Mode:量化迭代#
新增的 benchmark 模式会做标准化评估,追踪三个指标:
- eval 通过率
- 耗时
- token 用量
改了 skill 或者换了新模型,跑一遍 benchmark,数字说话。数据存本地,可以接 dashboard 或者塞进 CI。

多 Agent 支持:快一点,干净一点#
串行跑 eval 慢,而且上一个 eval 留下的 context 可能污染下一个。
新的多 agent 支持会并行起多个独立 agent 跑 eval,每个 agent 有自己干净的 context、独立的 token 和时间统计。更快,无交叉污染。
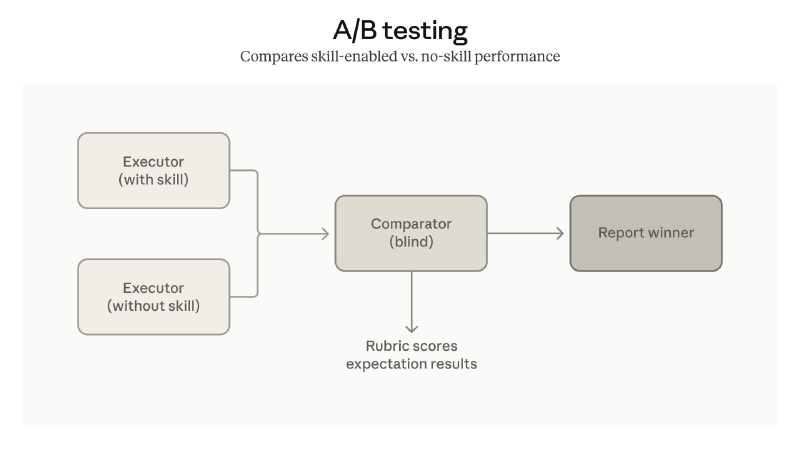
另外还加了 comparator agent:盲测两个版本的 skill(或者 skill vs. 无 skill),由 comparator 在不知道哪个是哪个的情况下评判输出质量。这样就能知道改动到底有没有效果,而不是靠感觉。
描述优化:触发对了才算赢#
eval 测的是输出质量,但前提是 skill 得在对的时候触发。
随着 skill 数量增多,描述精度变得很关键:太宽泛会误触发,太窄就永远不开。
新版 skill-creator 分析你的描述和样本 prompt,给出修改建议,减少假阳性和假阴性。Anthropic 在自家的文档生成 skill 上跑了一遍,6 个 skill 里有 5 个触发准确度提升了。

往前看:Eval 可能就是 skill 本身#
文章末尾有一段很值得琢磨:
随着模型进步,“skill” 和 “specification” 之间的界限可能会模糊。今天的 SKILL.md 本质上是一个实现计划——告诉 Claude 怎么做。未来,用自然语言描述 要做什么,让模型自己搞清楚剩下的,可能就够了。今天发布的 eval 框架是朝这个方向迈出的一步。Eval 已经在描述"做什么"了,最终,这个描述本身就可能成为 skill。
说直白点:现在我们写的 SKILL.md 是给 Claude 的操作手册,事无巨细。但模型变强了以后,你只需要描述目标和验收标准(也就是 eval),然后让 Claude 自己想办法实现。
skill 的形态可能会从"怎么做"变成"怎么评"。
在哪用#
整篇读下来,感觉 Anthropic 在把 skill 开发往工程化方向推——有测试、有基准、有 A/B,这套东西对于认真在用 skill 做工作流自动化的团队来说很有用。对于像我这种自己折腾的人,最实用的可能是 eval 和描述优化这两块。